现在很多人用 Claude Code、Cursor、Codex 写代码,刚开始会觉得效率很高:让 AI 写接口、修 bug、补测试、改文档,确实很快。
但用久了以后,会遇到一个更深的问题:
AI 会写代码,但它不一定懂你的项目。
它可能知道 Spring Boot、MyBatis、Redis、JWT,但它不知道你的项目里:
项目约定 | AI 容易出错的地方 |
|---|
Controller 只负责接收参数和返回结果 | AI 把业务逻辑写进 Controller |
Service 负责业务编排和事务 | AI 随便加事务或漏掉事务 |
接口统一返回 ApiResponse<T> | AI 直接返回 VO、Map、String |
业务异常统一走 BusinessException | AI 到处 try-catch |
DTO、Entity、VO 要分开 | AI 直接用 Entity 接收请求或返回前端 |
Mapper 只做数据访问 | AI 把业务判断写进 SQL 层 |
这些问题本质上不是 AI 不会 Java Web,而是它没有项目上下文。
Trellis 要解决的正是这个问题。
一句话概括:
Trellis 是一个面向 AI 编程助手的项目级规范、任务和记忆系统。
它不是新的 AI 模型,也不是新的开发框架,而是给 Claude Code、Cursor、Codex 等 AI 编程工具准备的一套“项目脚手架”。它把项目规范、任务上下文、开发记录保存到仓库里,让 AI 每次工作前都能重新读取这些信息。Trellis 文档
一、Trellis 解决的核心问题
没有 Trellis 时,AI 编程很依赖当前会话。
你在这次聊天里告诉它项目规范,它这次可能会遵守。但下次开新会话,很多信息就没了。你又要重新解释:
你反复解释的内容 | 示例 |
|---|
架构规则 | Controller、Service、Mapper 怎么分层 |
代码风格 | 命名、注释、异常、日志怎么写 |
业务约定 | 错误码、权限校验、分页格式 |
当前任务 | 这次到底要做什么,哪些不做 |
历史决策 | 为什么之前选择这种实现方式 |
Trellis 的思路不是让 AI “记住一切”,而是把这些知识写成项目文件。
也就是说:
AI 不需要靠脑子记住项目,而是每次工作前读取项目里的 Trellis 上下文。
二、Trellis 的三个核心模块
Trellis 最核心的是三个东西:Spec、Task、Workspace。
模块 | 位置 | 作用 |
|---|
Spec | .trellis/spec/
| 项目规范,告诉 AI 这个项目应该怎么写 |
Task | .trellis/tasks/
| 任务上下文,告诉 AI 这次具体要做什么 |
Workspace | .trellis/workspace/
| 会话记录,告诉 AI 之前做过什么 |
官方文档也把 Specs、Tasks、Workspace 作为 Trellis 的核心结构。Trellis 概览
换成 Java Web 项目来理解:
Trellis 模块 | Java Web 里的例子 |
|---|
Spec | 接口返回规范、异常规范、事务规范、分层规范 |
Task | 新增用户注册接口、重构订单状态流转、修复支付回调 bug |
Workspace | 上次为什么改了订单状态机、哪个接口还没补测试 |
三、Spec:把项目规范写给 AI 看
Spec 是 Trellis 最重要的部分。
它不是普通文档,而是 AI 每次开发前应该读取的项目规则。
比如 Java Web 项目里,可以把规范拆成这样:
文件 | 内容 |
|---|
.trellis/spec/backend/index.md
| 后端总规范 |
.trellis/spec/backend/api.md
| API 路径、请求、响应、分页规范 |
.trellis/spec/backend/service.md
| Service 层职责、事务边界 |
.trellis/spec/backend/database.md
| Mapper、SQL、分页、查询规范 |
.trellis/spec/backend/exception.md
| 异常、错误码、全局异常处理 |
.trellis/spec/backend/security.md
| 登录态、权限注解、接口鉴权 |
.trellis/spec/backend/testing.md
| 单元测试、集成测试、Mock 规则 |
关键是,Spec 不能写得太虚。
不好的规范:
不推荐写法 |
|---|
请写高质量代码 |
注意异常处理 |
保持代码整洁 |
遵循项目风格 |
好的规范应该具体:
规范项 | 推荐写法 |
|---|
Controller | Controller 不写业务逻辑,只做参数接收、参数校验、调用 Service、返回统一响应 |
Service | Service 负责业务编排和事务控制,涉及多次数据库写入的方法必须声明事务 |
Entity | Entity 只表示数据库结构,不允许直接作为接口请求或响应对象 |
Exception | 业务异常统一抛出 BusinessException,由全局异常处理器转换为统一响应 |
Response | 所有 HTTP 接口必须返回 ApiResponse<T>,分页接口返回 PageResult<T> |
官方也强调,好的 Spec 应该具体、可执行,最好包含路径、格式、正确例子和错误例子。写规范
四、Task:让 AI 知道这次任务的边界
Spec 解决的是长期规范,Task 解决的是当前任务。
比如你让 AI 做:
AI 可能会顺手做很多东西:注册、登录、JWT、短信验证码、用户表结构、权限系统,甚至重构现有模块。
Trellis 的 Task 会把需求整理成更明确的任务文件,比如:
内容 | 示例 |
|---|
Goal | 新增手机号注册接口 |
Requirements | 校验手机号、验证码、密码强度;手机号不能重复 |
Acceptance Criteria | 重复手机号返回指定错误码;验证码错误时注册失败 |
Out of Scope | 不做登录接口,不改权限系统,不做第三方登录 |
Technical Notes | 复用现有 UserService、SmsCodeService、UserMapper |
Related Specs | 读取 API 规范、异常规范、Service 规范、数据库规范 |
这样 AI 执行任务时,就不会凭感觉扩大范围。
它知道这次只做“手机号注册”,不是顺便把整个认证系统都写一遍。
五、Workspace:项目内的会话记忆
Workspace 保存的是当前项目里的开发记录。
它不是全局记忆,而是项目级记忆。
这点很重要。
记忆类型 | 适合放哪里 |
|---|
个人偏好 | Codex / ChatGPT 全局记忆 |
项目规范 | .trellis/spec/
|
当前任务 | .trellis/tasks/
|
项目开发记录 | .trellis/workspace/
|
比如你的个人偏好是:
个人偏好 |
|---|
写博客不要用代码块包列表 |
流程图用 Mermaid |
讲技术时先讲本质,再讲细节 |
这些适合全局记忆。
但下面这些应该放到 Trellis:
项目记忆 |
|---|
本项目接口统一返回 ApiResponse<T> |
用户模块不能直接返回 Entity |
订单状态流转必须经过状态机 |
支付回调必须保证幂等 |
Redis key 必须带业务前缀和版本号 |
一句话:
全局记忆记住“你这个人怎么工作”,Trellis 记住“这个项目应该怎么写”。
六、Trellis 的标准工作流
Trellis 不只是存文档,它还有一套围绕任务推进的工作流。
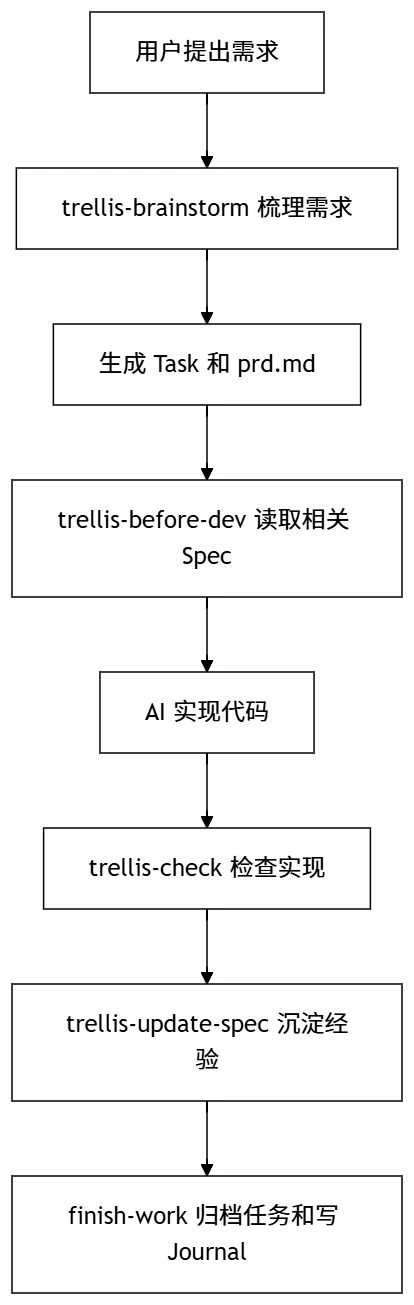
Trellis 0.5 之后偏向 skill-first,很多能力会通过 skill 触发,比如 trellis-brainstorm、trellis-before-dev、trellis-check、trellis-update-spec、trellis-break-loop。命令、任务与规范
结合 Java Web 项目看:
阶段 | 作用 |
|---|
brainstorm | 把接口需求、业务规则、边界条件问清楚 |
before-dev | 先读取 API、异常、事务、分层规范 |
implement | 修改 Controller、Service、Mapper、DTO、VO |
check | 检查是否违反项目规范 |
update-spec | 把踩坑经验沉淀到 Spec |
finish-work | 归档任务,写入开发记录 |
七、Trellis 和 Superpowers 的区别
Trellis 和 Superpowers 有重叠,但重点不一样。
对比 | Trellis | Superpowers |
|---|
核心定位 | 项目级上下文系统 | AI 开发方法论和 skill 集合 |
重点 | Spec、Task、Workspace | Brainstorm、TDD、Debug、Review |
记忆方式 | 写入项目 .trellis/ | 更多依赖 skill、plan、当前流程 |
多人协作 | 更适合团队共享项目规范 | 可以多人用,但不是主打项目记忆 |
防迷路能力 | 有任务状态和项目文件承接 | 更依赖模型自动触发或手动调用 |
适合场景 | 长期项目、团队项目、规范复杂项目 | 强流程开发、TDD、系统调试 |
更准确地说:
Superpowers 更像是“教 AI 怎么干活”。
Trellis 更像是“告诉 AI 在这个项目里应该怎么干活”。
如果你只想让 AI 更有纪律,Superpowers 很有价值。
如果你想让 AI 长期理解一个项目,Trellis 更适合做底座。
八、Java Web 项目如何落地 Trellis
不要一开始就写一堆规范。Trellis 更适合逐步沉淀。
推荐从三个最容易出问题的地方开始:
优先级 | Spec 内容 | 原因 |
|---|
高 | API 返回结构 | AI 很容易乱返回 |
高 | 分层职责 | AI 很容易把逻辑写错层 |
高 | 异常处理 | AI 很容易到处 try-catch |
中 | 事务规范 | 涉及写操作时容易漏事务或乱加事务 |
中 | DTO / VO / Entity 规范 | Java Web 项目很常见 |
中 | 测试规范 | 后续让 AI 补测试更稳定 |
低 | 日志、注释、提交信息 | 可以后面慢慢补 |
初期只需要让 AI 明确几条规则:
初始规则 |
|---|
Controller 不写业务逻辑 |
Service 负责业务编排和事务 |
Mapper 只负责数据访问 |
请求使用 DTO,响应使用 VO |
不允许接口直接返回 Entity |
业务异常统一使用 BusinessException |
接口统一返回 ApiResponse<T> |
分页统一返回 PageResult<T> |
然后让 AI 做一个小任务,比如“新增根据手机号查询用户信息接口”。
观察它有没有遵守规范。
如果没有,就把失败经验继续补进 Spec。
这才是 Trellis 的正确打开方式:
不是一次性写完所有规则,而是在真实开发中不断把经验沉淀成项目规范。
总结
Trellis 的本质不是让 AI 更聪明,而是让 AI 更懂你的项目。
它通过 .trellis/spec/ 保存项目规范,通过 .trellis/tasks/ 管理任务上下文,通过 .trellis/workspace/ 保存项目内会话记录。
对于 Java Web 项目来说,它尤其适合解决这些问题:
问题 | Trellis 的解决方式 |
|---|
AI 不遵守分层 | 写入 Controller、Service、Mapper 规范 |
AI 返回格式不统一 | 写入 API 响应规范 |
AI 异常处理混乱 | 写入异常和错误码规范 |
AI 任务容易跑偏 | 用 Task 和 PRD 限定范围 |
AI 跨会话断片 | 用 Workspace 保存项目记录 |
团队提示词不统一 | 用 Git 共享 .trellis/spec/ |

评论